让数据流得动、用得好、更安全——美创可信数据空间解决方案正式发布
2026-06-25
《金融信息服务数据分类分级指南》解读与美创数据安全分类分级落地实践
2026-06-23
国家网信办、工业和信息化部、公安部联合公布《网络数据安全风险评估办法》
2026-06-22
AI 驱动后渗透综合管理平台LeoAI部署与使用
2026-06-18
美创科技端午节假期值班公告
2026-06-18



存储域
数据库加密 诺亚防勒索访问域
数据库防水坝 数据库防火墙 数据库安全审计 动态脱敏流动域
静态脱敏 数据水印 API审计 API防控 医疗防统方运维服务
数据库运维服务 中间件运维服务 国产信创改造服务 驻场运维服务 供数服务安全咨询服务
数据出境安全治理服务 数据安全能力评估认证服务 数据安全风险评估服务 数据安全治理咨询服务 数据分类分级咨询服务 个人信息风险评估服务 数据安全检查服务平时,一定会有这样的经历:
1.在某宝或某东浏览了一个心仪的宝贝后,同一类别广告就占据了某宝和某东的显眼位置;
2.在某新闻APP,阅读了某类新闻,后续源源不断地推荐相似新闻;
3.在外卖平台上,搜索日料并成功下单,下一次相关店铺就会出现在排行榜前列。
……
这些场景的背后,离不开大数据平台的支撑。当下,大数据平台大行其道,BI系统架构亦逐渐融入大数据,相得益彰。
本文向大家介绍一下,几种常见的大数据BI系统架构:
01
传统BI大数据架构
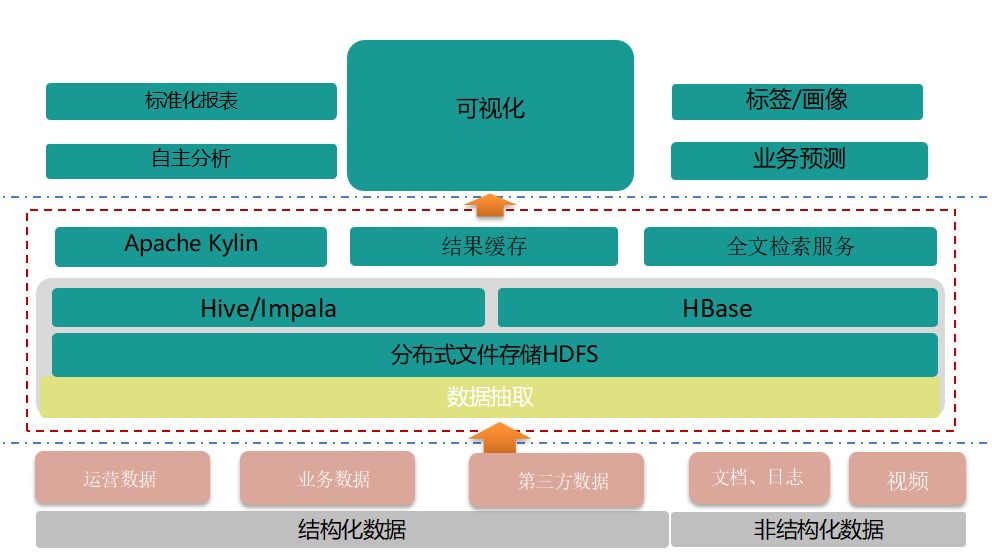
这种架构跟传统BI架构并没有太大区别,只是把存储数据的从关系型数据库换到了大数据平台上,解决了数据量和性能问题。
优点:简单、易用,因为和传统的BI架构没有太大区别,所以替换成本有限。
缺点:
1)无法满足大数据量的实时计算
2)对cube支持有限,因为kylin需要预先对cube进行定义,然后定时调度对cube进行计算和缓存
使用场景:离线分析、报表为主
02
流式架构
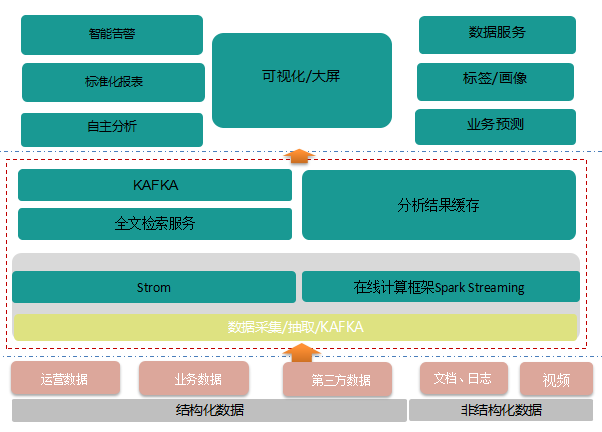
流式处理注重数据的时效性,通过对数据的实时计算和加工,呈现给数据消费者一段时间内的数据统计和分析。
优点:数据的时效性非常高
缺点:无法很好的对历史数据进行分析和计算
使用场景:监控告警平台、实时大屏展示等
03
Lambda架构
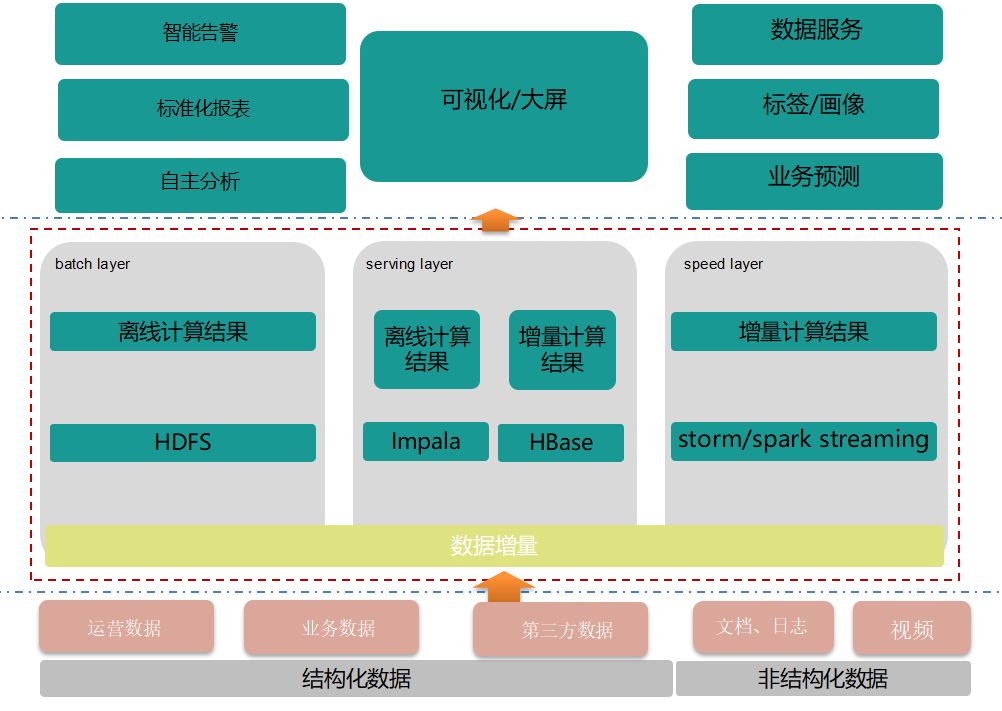
Lambda架构是由Storm的作者Nathan Marz提出的一个实时大数据处理框架,多年经验总结提炼而成。
Lambda架构的目标是设计出一个能满足实时大数据系统关键特性的架构,包括高容错、低延时和可扩展等。Lambda架构整合离线计算和实时计算,融合不可变性(Immunability),读写分离和复杂性隔离等一系列架构原则,可集成Hadoop、Kafka、Storm、Spark、Hbase等各类大数据组件。
优点:兼顾了实时处理和离线处理
缺点:存在数据重复处理
使用场景:多种分析混合使用场景
04
Kappa架构
Kappa架构是LinkedIn的Jay在使用Lambda架构后,结合自己的使用场景做的一个优化架构,主要解决的是重复劳动的问题,同样的分析结果两套不同的代码:实时处理和离线处理。
基于这个问题,Kappa架构引入了流计算系统对全量数据进行处理:
1.用消息队列存储需要处理的新鲜数据
2.当需要全量计算的时候,重新起一个流计算,从头开始处理数据,并输出结果
3.当新的结果生成后,删除老的流计算和结果
优点:成本较Lambda架构低,因为使用了一套架构处理两种数据,且开销相对较小,开发成本也低一些
缺点:离线数据吞吐量有限,因为每次离线数据需要从头计算,如果离线数据非常庞大,此时会消耗非常多的处理时间
使用场景:离线数据量不大,同时存在实时和离线数据处理,节省成本
大数据时代下,BI成为新热点,系统架构得以快速发展。未来的大数据会精准的找出我们的喜好,从而让烦人的广告变成有用的信息推送。
生活只会越来越美好~~
 官方订阅号
官方订阅号
 官方服务号
官方服务号
 第59号
第59号
 浙公网安备 33010502006954号
浙公网安备 33010502006954号