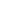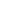AI 驱动后渗透综合管理平台LeoAI部署与使用
2026-06-18
美创科技端午节假期值班公告
2026-06-18
以智筑盾|美创科技多维入选《2026 AI+网络安全产业图谱》
2026-06-16
开源AI自主渗透智能体LuaN1aoAgent部署与使用
2026-06-15
庄荣文:坚持统筹发展和安全 不断做强做优做大数字经济
2026-06-12



存储域
数据库加密 诺亚防勒索访问域
数据库防水坝 数据库防火墙 数据库安全审计 动态脱敏流动域
静态脱敏 数据水印 API审计 API防控 医疗防统方运维服务
数据库运维服务 中间件运维服务 国产信创改造服务 驻场运维服务 供数服务安全咨询服务
数据出境安全治理服务 数据安全能力评估认证服务 数据安全风险评估服务 数据安全治理咨询服务 数据分类分级咨询服务 个人信息风险评估服务 数据安全检查服务
在大医院看病,可能都会有这样的体验:就诊大厅人来人往,挂号收费大排场龙,看个病各个流程走下来,要花费很长的时间。可要是这个时候,医院的就诊系统突然出现故障,那可不仅仅是增加就诊排队时间那么简单了,有可能还会耽误病人治疗,进而影响医患关系。

对于一家大型三甲医院来说,His系统运行的稳定性就显得更为重要了,不容有一丝的闪失。但往往一些小的数据库故障就会影响到系统运行的稳定性,导致医院就诊流程无法顺畅进行。此时,需要快速找出数据库故障原因并处理,恢复系统稳定。
前段时间,某医院His核心系统就频繁出现应用短暂卡住的现象,造成挂号收费窗口、护士站等“瘫痪”,人满为患、怨声载道。
医院信息部门无法查出问题所在,第一时间联系了美创科技的工程师。美创的工程师立马登录客户生产库查找原因,发现存在大量等待事件,伴随短暂的数据库锁等待。碰到这种情况,很多人想想当然的以为是应用程序的问题,误认为是更新程序的“后遗症”,想方设法抓语句提交给开发人员。其实这是一种误判。
根据美创工程师丰富的运维经验判断,这不像是一般的数据库锁等待,通过查看数据库alert日志,发现这套rac的alert的日志当中偶尔会出现实例重新配置的信息,并且两个节点在同一时间点都会发生。
此类问题在日常运维经验中并不常见,无法根据问题症状立刻给出及时和正确的解决思路。
工程师不抛弃不放弃,通过上述两点症状“按图索骥”,查找mos相关信息,判断是数据bug造成的问题,最后验证确实如此。找到了问题的根源,工程师在最短的时间内为客户提供了解决思路,有效地解决了问题,保证了大型医院his系统的正常稳定运行。

下面是满满的干货,详解“解题思路”
初步一看这个问题应该是rac crash了。继续排查alert日志,核实是否有实例crash后马上拉起来的日志,两个节点并没有发现实例重启的现象,但是两个节点在同一时间的alert日志当中都有相同的报错:
由上图可以看到,两个节点都报Global Resource Directory frozen错误,且在一分钟后很快又Reconfiguration complete重新配置
根据这个特征,去查询mos,找到DRM hang causes frequent RAC Instances Reconfiguration (Doc ID 1528362.1)
里面有四个症状特征:
症状特征一
- RAC Instances freezes during DRM for 100 secs or more.
RAC实例freezes 100秒或者更多(符合)
症状特征二
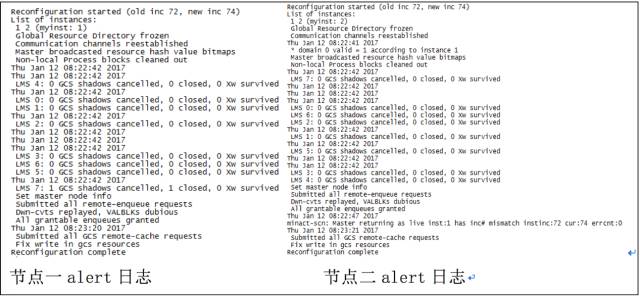
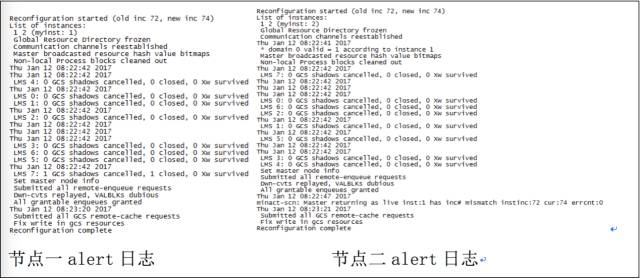
- DB Alert log shows that all RAC instances undergo reconfiguration at the same time, but there are no instance crashes
在相同时间数据库所有实例alert日志都显示重新配置,并且没有实例crash
由下图所得,(符合)
症状特征三
- Lmon trace shows that DRM quiesce step hangs:
*** 2012-07-14 14:14:51.187
CGS recovery timeout = 85 sec
Begin DRM(231) (swin 1)
* drm quiesce
*** 2012-07-14 14:17:03.752
* Request pseudo reconfig due to drm quiesce hang
2012-07-14 14:17:03.752735 : kjfspseudorcfg: requested with reason 5(DRM Quiesce step stall)
*** 2012-07-14 14:17:03.766
kjxgmrcfg: Reconfiguration started, type 6
CGS/IMR TIMEOUTS:
CSS recovery timeout = 31 sec (Total CSS waittime = 65)
IMR Reconfig timeout = 75 sec
CGS rcfg timeout = 85 sec
kjxgmcs: Setting state to 70 0.
Lmon trace显示DRM hang(符合)
- Lmon trace shows that DRM quiesce step hangs:
*** 2016-09-12 08:28:39.125
CGS recovery timeout = 85 sec
Begin DRM(40) (swin 0)
* drm quiesce
*** 2016-09-12 08:28:39.676
* drm sync 1
* drm freeze
* DRM(40) window 1, drm freeze complete.
* drm cleanup
* drm sync 2
* drm replay
* drm sync 3
* drm fix writes
症状特征四
- AWR Top waits are "gcs resource directory to be unfrozen" & " gc remaster "
在awr报告中的top 5等待会有gcs resource directory to be unfrozen和gc remaster等待事件。
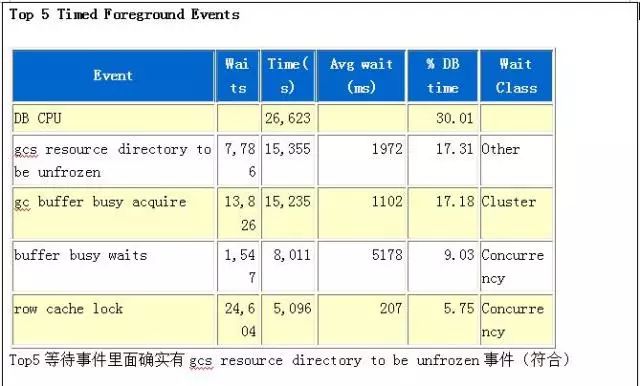
结论
依次比对了上述四大症状特征,可以判断此故障是由于Bug 12879027 引起的
DRM has a number of steps. During the DRM quiesce step all ongoing block transfers for remastering are completed.
In this case, during the DRM quiesce step a hang occured due to an internal function hitting a timeout.
This is a bug condition that happens when the buffer cache is very large.
This hang then triggers a pseudoreconfiguration to prevent the instance from being killed by another instance.
This is the reason for the instance undergoing a reconfiguration without restarting.
解决方案
既然我们已经找到了这个问题的症结所在,下面我们可以给出相应的解决方案。
方案1:关掉DRM
方案2:打上最新的psu
通常情况下,上述两种方案可以解决以上数据库问题。但由于环境的复杂性以及现场的多变性等客观条件,不能保证该解决方案的绝对成功,这里只提供类似问题的解决思路。真正解决问题时,请再考虑到一些客观因素,经过人为的思考,相信类似问题都能得到妥善解决。
 官方订阅号
官方订阅号
 官方服务号
官方服务号
 第59号
第59号
 浙公网安备 33010502006954号
浙公网安备 33010502006954号