全球数据跨境流动合作倡议
2024-11-22
世界互联网大会|美创数据库保险箱(DBSafe)发布!
2024-11-21
世界互联网大会|美创数据认知与分类分级系统(AICogniSort)重磅发布!
2024-11-21
美创案例|盐城公积金管理中心数据安全创新实践
2024-11-15
5=1!美创科技在中国数据安全软件市场主要厂商份额位列第五
2024-11-01



存储域
数据库加密 诺亚防勒索访问域
数据库防水坝 数据库防火墙 数据库安全审计 动态脱敏流动域
静态脱敏 数据水印 API安全 医疗防统方运维服务
数据库运维服务 中间件运维服务 国产信创改造服务 驻场运维服务 供数服务安全咨询服务
数据出境安全治理服务 数据安全能力评估认证服务 数据安全风险评估服务 数据安全治理咨询服务 数据分类分级咨询服务 个人信息风险评估服务 数据安全检查服务 作为数据密集型和科技驱动型行业,越来越多的金融行业机构开始尝试采用数据驱动的方法来促进自身业务的升级转型。然而,随着大量生产数据应用在开发、测试、提取和分析挖掘等场景,敏感隐私数据泄露的风险也愈加严重。同时,国家在保护敏感、涉密数据安全方面也不断出台、完善相关法律法规、方针政策,防止敏感数据泄露。
01金融行业法规要求
1、《中国银行业“十二五”信息科技发展规则监管指导意见》:“加强数据、文档的安全管理,逐步建立信息资产分类分级保护机制。完善敏感信息存储和传输等高风险环节的控制措施,对数据、文档的访问应建立严格的审批机制。对用于测试的生产数据要进行脱敏处理,严格防止敏感数据泄露。”
2、《金融行业网络安全等级保护实施指引》:应将开发环境、测试环境、实际运行环境相互分离,敏感数据经过脱敏后才可在开发或测试中使用。
3、《金融数据 安全数据生命周期安全规范》:开发测试等过程的数据,应事先进行脱敏处理,防止数据处理过程中的数据泄露,国家及行 业主管部门另有规定的除外。
4、《商业银行信息科技风险现场检查指南》: “开发过程中是否使用了生产数据,使用的生产数据是否得到高级管理层的批准并经过脱敏或相关限制。”“测试用例是否有生产数据,当使用生产数据测试时是否得到高级管理层的审批并采取相关限制及进行脱敏处理。”
02金融行业场景分析
1、安全管理要求较高:金融行业内部组织架构较为复杂,数据脱敏需求往往会涉及到安全、测试、业务、数据等多个部门,因此脱敏系统需要具备安全管理能力,如用户多级管理功能、脱敏任务审批功能等。
2、数据类型较为复杂:金融行业的数据类型较为复杂,脱敏需求涉及到的数据库种类较多,典型的如Oracle、MySQL、DB2、AS/400(DB2)、SQLServer等,还需要支持如TDSQL、星环、HIVE、IMPALA、PostgreSQL等数据类型,脱敏系统不光需要有较强的兼容性,快速对接一些新的数据源的能力,也十分重要。
3、数据规模较为庞大:金融行业开发测试任务较重,这就导致了脱敏需求较为旺盛,且需要脱敏的数据量往往较大。每周的脱敏数据量往往能够达到TB级别,因此脱敏速度要求较高,脱敏系统还需要支持分布式部署,提升整体脱敏效率。
因此,满足金融行业脱敏高要求的脱敏产品,具有以上特点。
03实施技术及过程解析
1数据脱敏使用场景
| 类型 | 常用场景 | 具体例子 |
| 静态数据脱敏 | 静态数据脱敏通常用于非实时场景。 | 将生产环境中的数据脱敏用于测试环境。 |
| 动态数据脱敏 | 动态数据脱敏通常用于生产环境等实时场景,在应用或平台用户访问敏感数据的同时进行脱敏,用于解决根据不同情况对统一敏感数据读取时需要进行不同级别、类型脱敏的场景。 | 适用于对生产数据共享或时效性很高的数据访问场景等,实现对生产数据库中的敏感数据进行透明、实时脱敏。 |
敏感数据识别
对生产系统中敏感数据的识别,主要包括:
a)存储位置:明确敏感数据所在的数据库、表、字段(列);
b)数据分类、分级:明确敏感数据所属类别及敏感级别。
策略选择、算法配置
脱敏算法配置主要包括:数据脱敏后保持原始特征的分析、数据脱敏算法的选择和数据脱敏算法参数配置。
a)保持原始数据的格式、类型;
b)保持原有数据之间的依存关系;
c)保持引用完整性、统计特性、频率分布、唯一性、稳定性。配置需要脱敏的目标(数据库名/表名/字段名)以及适当的脱敏算法参数,根据业务需求完成其他算法的参数配置。
数据脱敏处理到脱敏结束
动态脱敏处理步骤:
步骤1-协议解析:解析用户、应用访问大数据组件网络流量;步骤2-语法解析:对访问大数据组件的语句进行语法分析;
步骤3-脱敏规则匹配:根据用户身份信息及要访问的数据;步骤4-下发脱敏任务:由脱敏引擎调度脱敏任务;
步骤5-脱敏结果输出:将脱敏后的数据输出,保证原始数据的不可见。
大数据平台将所有数据整合起来,充分分析与挖掘数据的内在价值,为业务部门提供数据平台,数据产品与数据服务。用户隐私数据保护与挖掘用户数据价值是自相矛盾体,完整的数据脱敏需要抹去全部的用户标识信息,使得数据潜在的分析价值降低。针对于大数据脱敏平台的设计目的在于数据泄露风险可控、可管理、可审计。
1、流式数据脱密
流式数据是指不断产生、实时计算、动态增加且要求及时响应的数据,它具有海量和实时性等特点,一般将实时或准实时的数据处理技术归为流式数据处理技术。
a)基于storm的流式数据脱敏
STORM 是一个分布式,可靠的,容错的数据流处理系统。Storm集群的输入流由一个被称作spout的组件管理,spout把数据传递给bolt,数据保存到某种存储器,或者传给另外一个bolt。Storm的数据处理方式是增量的实时处理,当并没有全量的数据,可以去读取历史数据并结合相应的算法进行数据脱敏,依据脱敏规则将数据做泛化处理,它的优势就在于数据发生即进行数据处理。不足之处是无法利用全量数据做复杂的关联处理。
b) 基于sparkstreaming的流式数据脱敏
当有微批处理,且有状态计算恰好是一次的递送,并且不介意高延迟,就可以考虑使用sparkstreaming,它的优势可以提供一体化编程模型,尤其是数据流算法并允许Spark实时决策的促进。
2、批量数据脱敏
适用场景数据源是一个稳定的、基本不变的存储介质,并通过数据扫描的方式一次性将数据采集到大数据平台来,数据以历史数据为主,包括一般文件、关系型数据库、nosqL数据库等。处理技术包括:flume、sqoop等。批量数据脱敏可以在数据导入的过程中进行脱敏,也可以在数据进行大数据平台后,调用脱敏模块来进行脱敏。Sqoop是适用于关系型数据库的数据采集,可以通过建立中间表,编写udf程序的方式,最后通过任务调度程序,批量的对数据进行数据脱敏。
4、数据脱敏策略
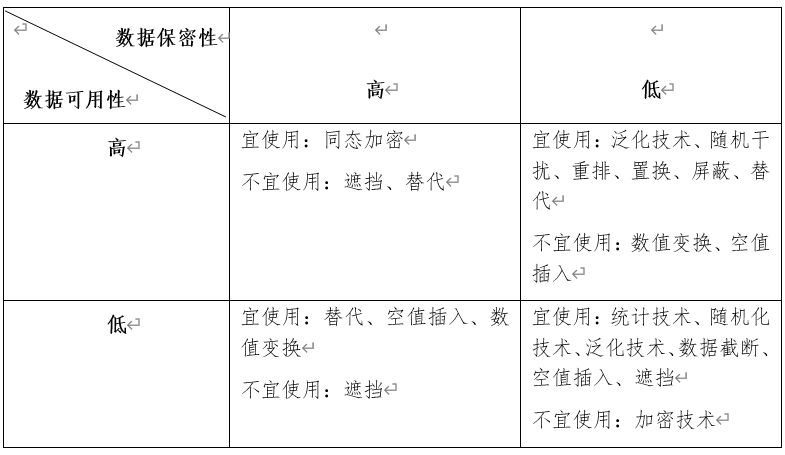
在设定具体场景下数据脱敏策略时应充分考虑数据脱敏后数据自身可用性及数据保密性寻求两者间的平衡。数据脱敏策略的选择如下显示。数据脱敏的目标包括:
a) 避免攻击者识别出原始个人信息主体;
b) 控制重标识的风险,确保重标识风险不会增加;
c) 在控制重标识风险的前提下,确保脱敏后的数据集尽量满足其预期目的;
d) 选择合适的数据处理方式保证信息攻击成本不足以支撑攻击动机。
5脱敏算法规则
| 算法 | 描述 | 适用数据类型 | 推荐脱敏形态 |
| 重排 | 跨行随机互换原始敏感数据,打破原始敏感数据与本行其他数据关联关系。 | 通用 | 动态脱敏、静态脱敏 |
| 关系映射 | 原始敏感数据间存在业务关联关系,需要在数据脱敏后仍旧保持关系。因此在脱敏处理中,利用算法表达式对脱敏后的数据进行函数映射,使其脱敏后仍旧保持业务关联关系。 | 通用 | 动态脱敏、静态脱敏 |
| 偏移取整 | 按照一定粒度进行偏移取整。 | 日期、时间、数字 | 动态脱敏、静态脱敏 |
| 散列 | 对原始数据通过散列算法计算,使用计算后的散列来代替原始数据。 | 通用 | 动态脱敏、静态脱敏 |
| 加密 | 通过加密密钥和算法对原始数据进行加密,从而使敏感数据变成不可读的密文。 | 通用 | 静态脱敏 |
| 格式保留算法(FPE) | 一种特殊的加密脱敏算法,对敏感数据进行加密脱敏,密文与原始数据保持格式一致。 | 通用 | 静态脱敏 |
| 常量替换 | 使用常量伪装数据对原始数据进行替换(伪装数据生成与原始数据值无关)。 | 通用 | 动态脱敏、静态脱敏 |
| 随机替换 | 保持数据格式,按照特定原始数据的编码规则重新生成一份新的数据。 | 通用 | 动态脱敏、静态脱敏 |
| 截断 | 截断内容 | 通用 | 动态脱敏、静态脱敏 |
| 标签化 | 按照预定类别进行分类,将使用类别标签替换原始敏感数据。 | 通用 | 动态脱敏、静态脱敏 |
| 泛化 | 用更一般的值取代原始数据,降低敏感数据精确度,达到无法识别个体的目的。 | 通用 | 动态脱敏、静态脱敏 |
| 匿名 | 通过对数据内容的处理,保证在数据表发布时,数据中存在一定量的准标识符上不可区分的记录。 | 通用 | 静态脱敏 |
| 差分隐私 | 在原数据中加入噪音信息,使得满足差分隐私的数据集能够抵抗任何对隐私数据的分析。 | 数据集 | 数据脱敏 |
| 浮动 | 通过浮动脱敏算法,上浮、下降5%。 | 数据集 | 静态脱敏 |
| 归零 | 通过归零算法对原数据381.38进行脱敏。 | 数据集 | 静态脱敏 |
| 均化 | 通过均化算法进行脱敏。 | 数据集 | 静态脱敏 |
| 分档 | 将数据按照规模分为高、中、低三档,分别进行脱敏。 | 数据集 | 静态脱敏 |
| 掩码 | 对原始数据的部分内容用通用字符进行统一替换,从而使敏感数据仅保持部分内容公开。 | 字符串 | 动态脱敏、静态脱敏 |
1)美创目前已经内置的脱敏算法
| 算法名称 | 算法说明 | 示例 | 使用场景(仅做参考) |
| 固定映射 | 通过设置映射种子,在映射种子不变的情况下,相同原数据脱敏后结果相同,并保留原始业务特征 | 映射种子:111 原数据:张三 一次脱敏结果:李四 二次脱敏结果:李四 | 中文姓名、身份证、电话、银行卡、电子邮箱、地址、IP地址 日期、通用字符串、键、货币金额 医疗机构登记号、医师资格证书、医师执业证书 营业执照、社会统一信用代码、组织机构代码、税务登记证、开户许可证 护照、军官证、中国护照、港澳通行证、永久居住证、台湾同胞大陆通行证 证券名称、证券代码、基金名称、基金代码 |
| 随机映射 | 对数值、字符或字符串进行随机,并保留原业务特征 | 原数据:19841222 脱敏结果:19900211 | 中文姓名、身份证、电话、银行卡、电子邮箱、地址、邮政编码、IP地址 CCV码 货币金额、通用字符串、字符串 医疗机构登记号、医师资格证书、医师执业证书 营业执照、社会统一信用代码、税务登记证、开户许可证、组织机构代码、组织机构名称 护照、军官证、中国护照、港澳通行证、永久居住证、台湾同胞大陆通行证 证券名称、证券代码、基金名称、基金代码 |
| 遮盖 | 通过设置遮盖符,对原数据全部或部分进行遮盖处理 | 遮盖符:* 原数据:13512345678 脱敏结果:135****5678 | 中文姓名、身份证、电话、银行卡、电子邮箱、地址、CCV码、IP地址 组织机构代码、组织机构名称、营业执照、社会统一信用代码 医疗机构登记号、医师资格证书、医师执业证书 护照、税务登记证、开户许可证、军官证、中国护照、港澳通行证、永久居住证、台湾同胞大陆通行证 证券名称、证券代码、基金名称、基金代码 |
| 范围内随机 (泛化脱敏) | 对日期或金额,在一个指定的范围内进行随机,并保留原业务特征 | 范围1000至9999 原数据:38472.00 脱敏结果:8394.00 | 日期 货币金额 通用数值 |
| 保留随机 | 选中分段保留,其他分段随机 | 原数据:2020年10月10日 脱敏算法:【1900-2018】年、【01-12】月、【01-30】日 | 日期 |
| 浮动 | 对日期或金额,上浮或下降固定值或百分比,并保留原业务特征 | 上浮、下降5% 原数据:1000.00 脱敏结果:1049.00 | 日期 |
| 归零 | 对于数值,清空并置为0.00 | 原数据:381.38 脱敏结果:0.00 | 通用数值 |
| 截取 | 对字符串按照起始位置进行截取 | 开始位置:2,结束位置6 原数据:abcdefghijk 脱敏结果:bcdef | 通用字符串 |
| 截断 | 对字符串保留除起始位置意外的内容 | 开始位置:2,结束位置6 原数据:abcdefghijk 脱敏结果:aghijk | 通用字符串 |
| 数字截断 | 将数字截断,只保留指定位数 | 如12345678,保留“3位”,则为678。 | 通用数值 |
| 加密 | 通过不同的加密算法进行加密,脱敏后显示的数据为密文数据 | SHA1加密、MD5加密、SHA256加密、AES对称加密、RSA非对称加密、SMS4加密等 | 中文姓名、身份证、电话、银行卡、电子邮箱、地址、IP地址 邮政编码(SHA1加密、MD5加密) 营业执照、社会统一信用代码、组织机构代码、税务登记证、开户许可证 医疗机构登记号、医师资格证书、医师执业证书 护照、税务登记证、开户许可证、军官证、中国护照、港澳通行证、永久居住证、台湾同胞大陆通行证 证券名称、证券代码、基金名称、基金代码 |
| 替换 | 将数据替换为一个常量,常用作不需要改敏感字段时 | 原值:566 原值:789 脱敏后: 566 - 0 789 - 0 | 通用字符串 |
| 匹配替换 | 通过EXCL表格导入替换规则,完成匹配替换 | 1111替换为2222 3333替换为4444 | 通用字符串 |
| 水印 | 通过数字水印打上水印标签 | 伪行、伪列或者不可见字符 | 日期 |
| 偏移 | 小数点往左或往右进行偏移 | 如设定偏移量【2】,则脱敏结果可能为【28.00】 | 货币金额 通用数值 |
| 取整 | 对数字位数进行取整 | 如取整位数为2,则1988.65脱敏后为1900 如12345678,整数“3位”,则为12345000 | 货币金额 通用数值 |
| 分段 | 主要针对数字进行脱敏,可以将同一范围的数值脱敏为相同的数值 | 如1~99的数值,统一脱敏未1 100~199的数值,统一脱敏为2 200~299的数值,统一脱敏为3 | 货币金额 |
2)其它脱敏算法
| 算法名称 | 算法说明 | 示例 | 使用场景(仅做参考) |
| 均值脱敏 | 我们先计算它们的均值,然后使脱敏后的值在均值附近随机分布,从而保持数据的总和不变。 | 如学科总分500分 脱敏后各科学分相加还是为500分。 | 货币金额 |
| 哈希 | 将数据映射为一个hash值 | Jim,Greenà456393 34453 | 用作将不定长的数据映射为定场的hash值。 |
 官方订阅号
官方订阅号
 官方服务号
官方服务号
 第59号
第59号
 浙公网安备 33010502006954号
浙公网安备 33010502006954号